Why Does Your Project Need the Best Software Architecture?

For many people, the concept of software architecture can sometimes feel very vague. What is software architecture? This term describes how developers and program managers to design and combine software components. It's analogous to a building architect. Instead of walls, beams, concrete, and other physical things, there are software components. Example components include microservices, clients, servers, and interfaces. Why is software architecture so important? Much like a physical building, the wrong architecture will lead to significant issues. The right architecture will make developing your software much more straightforward.
Indeed, without the best software architecture, your site or app will run into issues. Bad architecture might mean your site doesn't scale very well. It could also mean those changes are challenging to make, or you'll need a complete rewrite in the future. By contrast, having a stellar design ensures your software scales well. It also ensures it is easy to customize and has a longer life.
Given that having the right architecture is essential, let's dive into this topic more. Here's what you need to know about software architecture in practice. We'll also discuss why your project needs to have the right design to start so you will understand why software architecture consulting is absolutely necessary.
What Is Software Architecture?
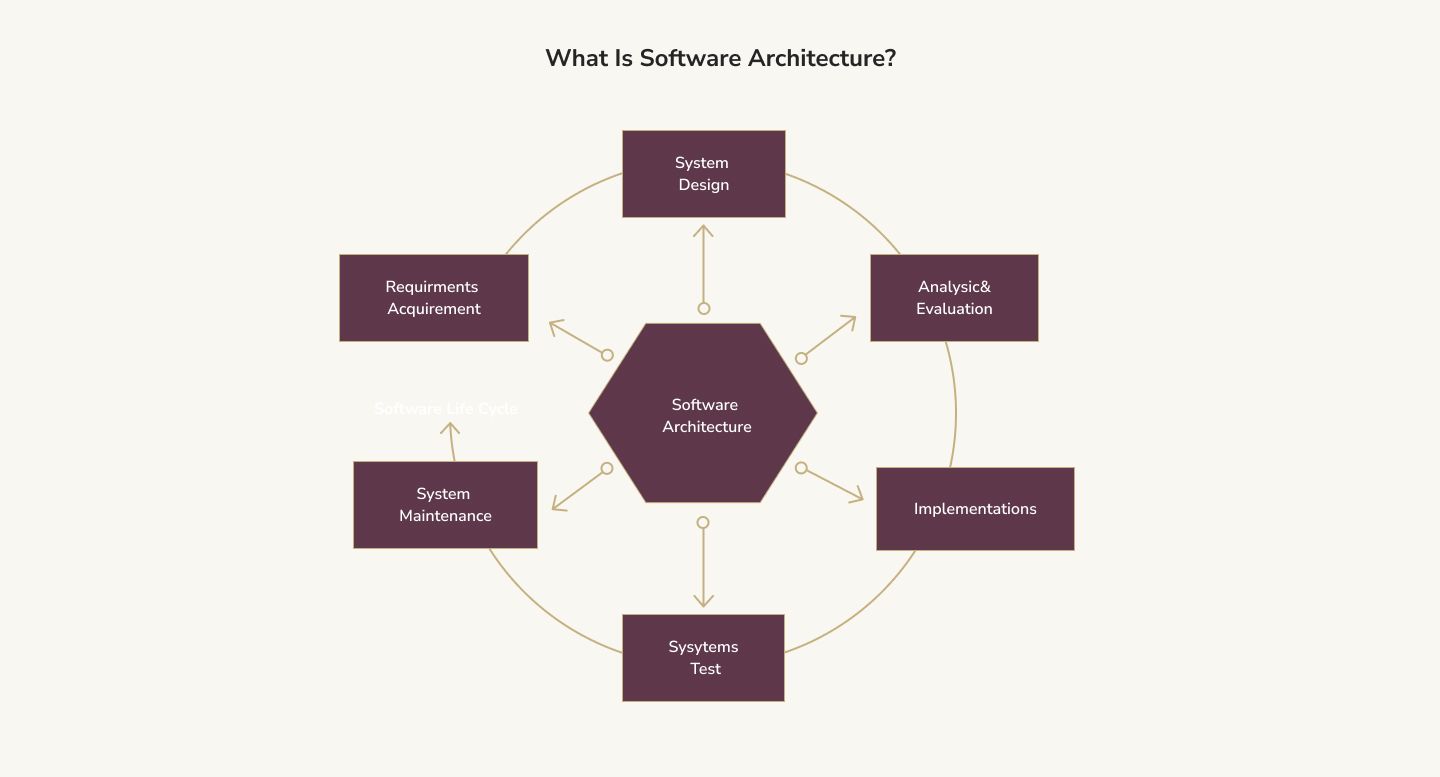
To understand why software architecture is so vital, it's important, first, to know what this topic encompasses.
As mentioned above, software architecture is about defining and connecting individual software components. This process requires understanding the entire solution and breaking it down into smaller pieces.
For example, let's suppose you have a news site. You'll have three broad components — a client app, a web app, and a server. Both the client app and the web app communicate with the server via an interface. The server may use a microservices architecture to scale up or down as necessary (add more servers with load, and reduce them after to save money).
This example is simple but gives a good idea of what software architecture is. The fundamentals of software architecture are not about the code written or even necessarily about the implementation details (Kubernetes, Docker, etc.). Instead, it's about the building blocks which give the project the foundation and strength necessary to succeed, taking into account software architecture quality attributes.
What Is the Difference Between Software Architecture and Other Software Disciplines?
You may have heard three terms before — software architecture, software design, and software engineering. We've already discussed what software architecture is. What about the other two? What if we compare software engineer vs architect and software architecture vs software engineering? Although they might sound similar, each component plays a vital role in the software development cycle.
Software Design
Software design ensures that the code written adheres to well-known and tested best principles. What are the principles of the design process in software engineering? There are countless best design principles, and listing them all would be beyond the scope of this post. Here are three of the top ones:
- Single Responsibility: A class or object should not be responsible for more than one thing. For example, if we're writing a hockey video game, we'd have a Player class, a Puck class, a Goal class, and so on. It would make no sense to have a PlayerAndGoal class, where the one class handled both the player's movements and whether the user scored a goal. Each class should manage one thing in your program.
- Liskov Substitution Principle: This term is a fancy way of saying that derived classes should not rewrite the base class. As a simple example, suppose you have a class called Dog with a method called "Bark." If you're writing a Basenji class (this dog yodels instead of barking), you shouldn't override "Bark" with the logic to make it yodel. This override may not be easy to understand. Instead, Basenji should have a new method called "Yodel." Subclassed methods should not return something different than their parent classes.
- Dependency Inversion: High-level modules should never depend on lower ones. In other words, a Car class shouldn't care about how Engine.start() works. It should be able to call Engine.start() and know the car can now move forward.
If you're interested in learning more about software design, this resource is a place you may want to start.
Software Engineering
Despite popular belief, software engineering is not about the code.
Software engineers do sometimes write code. What is the main aim of software engineering? It's to produce a high-quality product. This goal incorporates the right architecture. It also has robust design principles and adheres to the requirements. It also should focus on testability and maintainability.
Software engineering incorporates each of these disciplines to produce quality code, which powers many of the experiences you use daily.
What Is the Best Software Architecture?
You may be wondering if there is a "best" software architecture. After all, if there was a universally "best" architecture for software, why wouldn't everyone use it? They would bypass some of the pitfalls that cause havoc for other projects.
Unfortunately, there is no singular best software architectural practice. Even the software solution architecture best practices always have benefits and drawbacks. Other architectural decisions will almost always result in problems.
The best software architecture is almost always dependent upon your project's requirements. So, you'll need a skilled software architect (or a company that deals with software architecture) to create the architectural blueprint for your project's success.
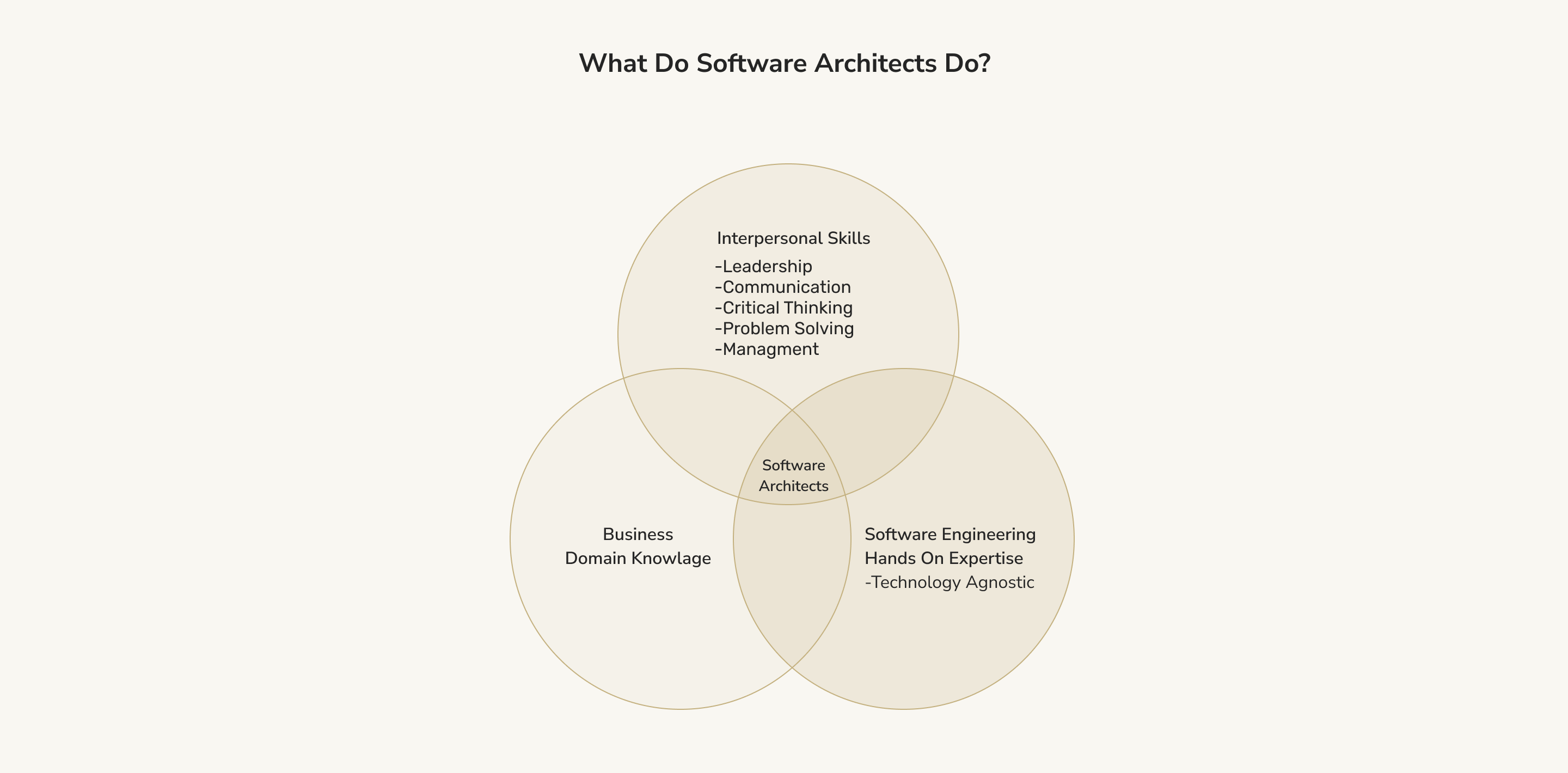
What Do Software Architects Do?
If you choose to hire a software architect, they will handle a few primary duties. Each of these is vital to arriving at a high-quality solution. Please note that the role of the software architect in the process is very hands-on. It is their responsibility to ensure that the software adheres to best practices.
First, a software architect must understand and report to various stakeholders about requirements. Consider an online ordering app for a restaurant. A software engineer architect would sit down with the owners and discuss what this app needs to do. Throughout the development process, the software architecture consultant would also report to the stakeholders. They'd receive news about progress. The software development architect would incorporate any revised requirements as well.
Software architecture consultant then takes those requirements and crafts design documents and product specifications considering all quality attributes in software architecture. These high-level documents explain what the program must do. There's no code here, but these documents are often quite detailed.
After the stakeholders consider all these documents, software architects will craft detailed specifications. These are for engineers and developers. Sequence diagrams, UML diagrams, or written documents will describe the specifications. Developers will need to follow these specs to create the software.
Once development is underway, the software engineer architect will still work with developers. They'll test the product and ensure its quality. They'll continue to work with all stakeholders as difficulties or requirements changes arise.
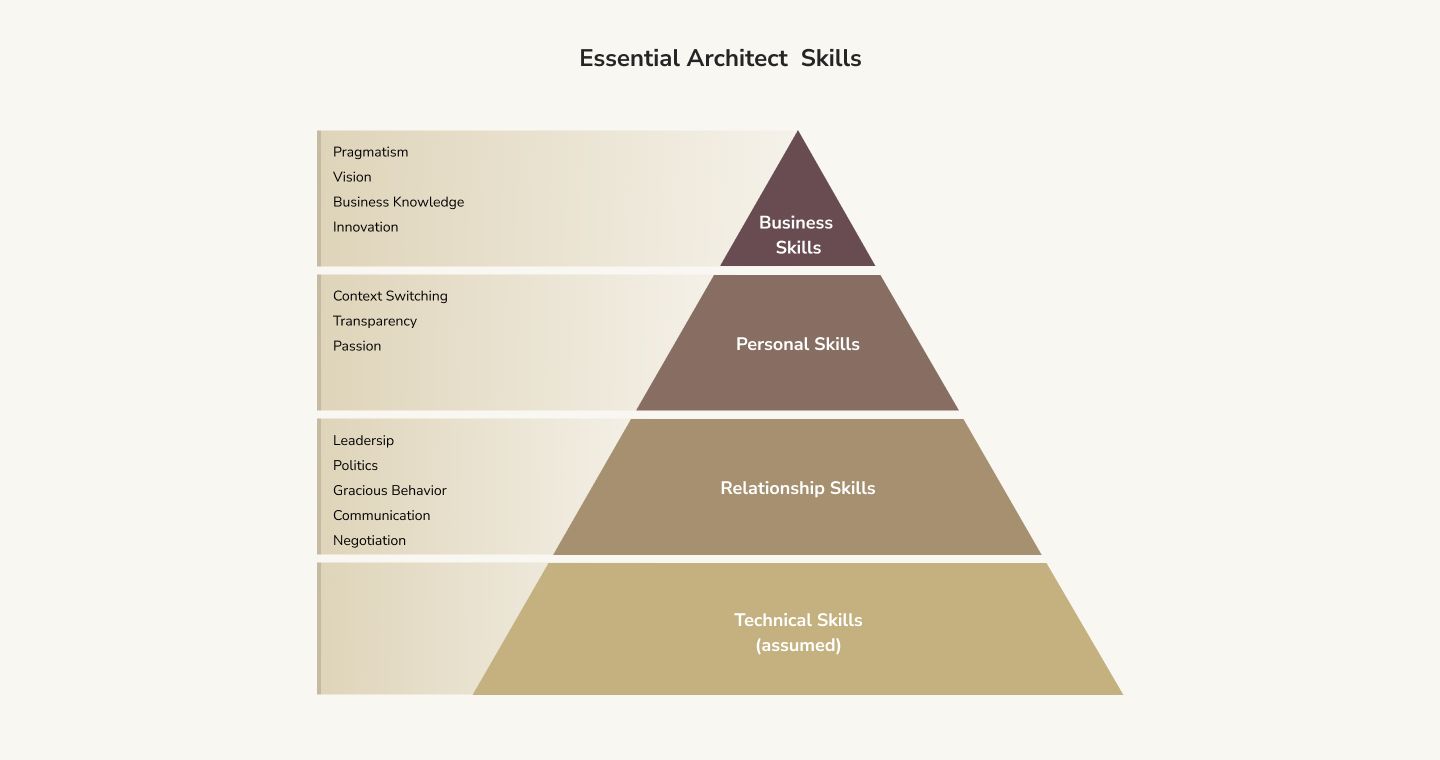
What Skills Do You Need to Be a Software Architect?
Programmers need to know how to program. Designers must design. And, yes, you guessed it, software architects must know how to architect software solutions. In particular, software architects need to know quite a bit about the software development process. They need to understand how to distill customer requirements into software solutions that adhere to the best practices. They need to design and create comprehensive documents for engineers and developers to follow. As you might imagine, software architects often need to bridge the gap between linguistic requirements (I want a site that lets people buy shoes) and technical ones (this should have a serverless architecture with an interface to PayPal for payment processing).
At this point, you might be wondering, "do software architects write code?" Usually, software architects will write a little bit of code. They sometimes write the initial starting project to demonstrate to developers and engineers a simple proof-of-concept upon which talented programmers can expound. However, their day-to-day job has little coding in it. Most of the time, all types of software architects will be writing, drawing diagrams, or sitting in meetings with stakeholders.
For people who are presently coding and want to transition to a more architectural role, the question is, can a software engineer become a software architect? Absolutely. Most software architects were former engineers or had a lot of exposure to engineering and just proceeded to get software architecture certification. The job would be a little tricky to do if you had no idea of programming or engineering.
However, it's worth noting that while engineers may become architects, software developers would run into more problems. When thinking about what is the difference between a software developer and a software architect, there's quite a bit that separates them. Software developers write code. They don't get involved as much in the system architecture or how to engineer the best solutions. They tend to receive specs and turn those into code. That's very much different than what an architect does. However, we would recommend listening to software architecture podcast or reading some software architecture blogs to dive into the topic deeper.
What Is a Software Framework?
Software frameworks form the foundation for most application development. A framework is an abstraction of more complex computing problems that enables a developer to write code more efficiently. It's a set of prefabricated building blocks that developers can piece together to create comprehensive solutions.
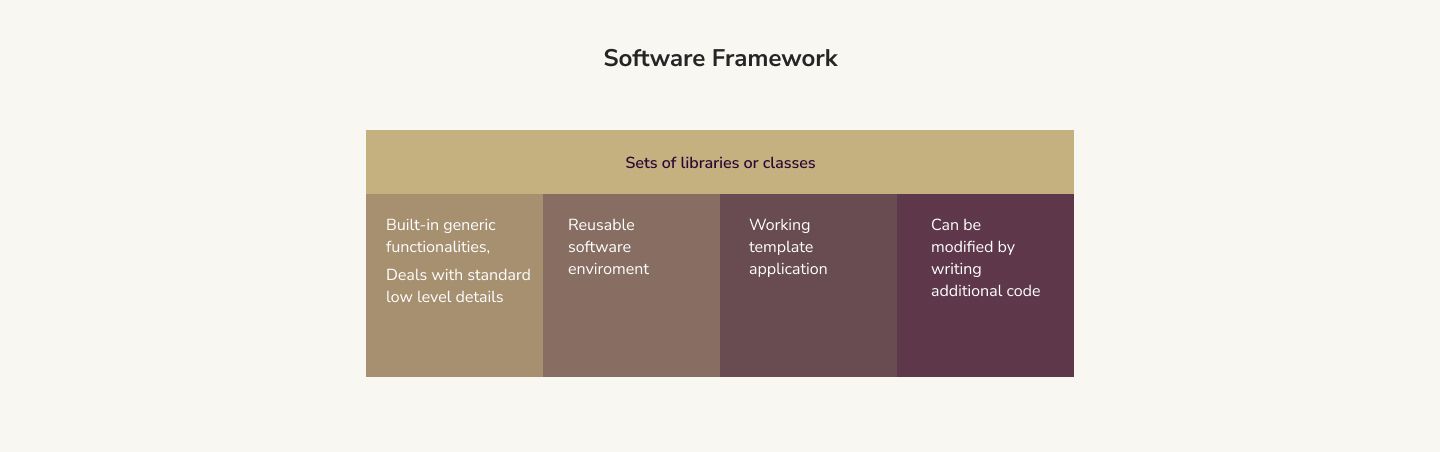
A fantastic example of a software framework is .NET for Windows development (which is now for Mac OS X and Linux as well). C# is a programming language by Microsoft, but .NET is the framework containing all the building blocks to create stellar applications and services on the Windows platform. For example, you can use WinForms to create windows, the System.Net library for networking commands, and the System.IO namespace for everything relating to disk reads and writes.
If you're looking to program games for Windows, there's DirectX. For Mac OS X, there's Metal. For all operating systems, OpenGL is a fantastic software framework for rendering graphics.
Software architects must choose the right software framework to use. It should accurately reflect the best software architecture for the solution.
What Is the Difference Between Architecture Frameworks and Patterns?
Software frameworks and patterns might seem similar at first. If you select the right software framework, wouldn't this choice lead you to the proper architectural practice by default? If you pick Python and Django, for example, doesn't that kind of pick the way you're going to design your application?
The answer to this question depends mostly on your selected framework. Usually, a software framework has various components and architecture design patterns built into it. For example, Laravel for PHP adheres reasonably firmly to the MVC layered architecture. However, the PHP language itself is a software framework as well, and you can write a program with any architecture with it.
Therefore, software frameworks typically have recommended best practices and patterns. Some of the more granular frameworks (like Laravel, Drupal, WordPress, Django, and ASP.NET MVC) will work best with particular software architecture in practice. However, as is the case with anything in software, you can always adjust the code to suit your specific needs. If you like Django and want to use it to implement backend microservices, you can certainly do so, even if that's not its primary use case.
How To Select the Right Software Architecture Pattern?
There's no concrete algorithm for finding the right software solution architecture pattern for any given requirements. Each project is unique, so there's often no "one-size-fits-all" architecture that will work for your project. Instead, most software architects must combine multiple patterns and best practices to create a tailored solution that will work for your business needs.
As a quick example, let's say you're opening an online store. The architecture you'd choose to handle 600 purchases a second (Amazon had this four years ago) is much different than the architecture you would use to accept three purchases per day. To take 600 purchases per second, you'd need extensive load balancing, a microservice architecture, lots of security, and a massive cloud bill. For three a day, a WooCommerce WordPress site might suffice.
With that said, here are the most common types of software solution architecture, including their benefits, drawbacks, and some examples of when a software architect might decide to use it.
Layered (n-tier) Architecture
Layered architecture is arguably the most common. Many of the most prominent frameworks (Drupal, WordPress, Java EE, and others) use an n-tier architecture. They use it for a good reason, though. Most business applications tend to fall into this approach naturally.
You can think of an n-tier architecture like a layer cake.
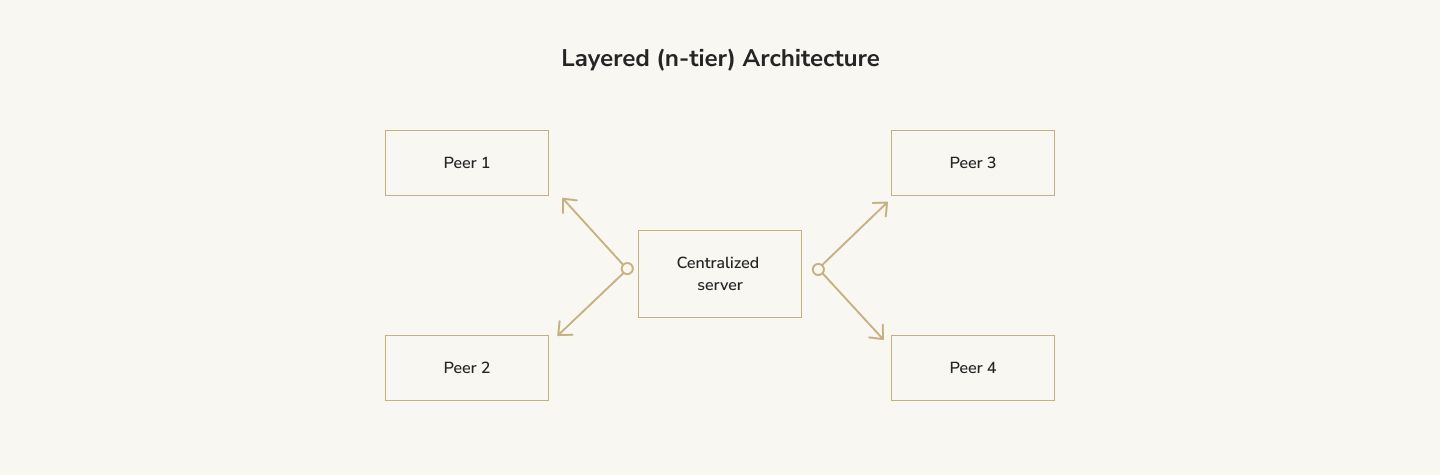
The bottom layer is your application's raw data, the foundation. This data could be the products you offer in your store or the content you want your app to display. Then, you build some code to convert that raw data into a format your application can use with a little bit of business logic (e.g., full name is first name and last name). In most paradigms, this code is the model.
Next, you want a way to display this information. So layered architecture in software engineering builds the next layer, the view, on top of the model. This layer allows the application to present the data in different ways. On top of that, you'll want a way to modify the data. This layer is called the controller.
Since most applications follow the MVC (model-view-controller) paradigm, many software programs you use daily have this type of app architecture design.
Benefits: Part of what makes this architecture so powerful is its simplicity. Everyone can quickly grasp it because each layer makes perfect logical sense. It also adheres to the separation of concerns principle in software design. Each layer handles one aspect of the application. Therefore, you can quickly test it. The layer below provides the information you can mock, and you can verify that the output makes sense for the layer above it.
Drawbacks: There's a bit of a catch-22 of this one of software architecture patterns. Many times, intermediary layers aren't always necessary. If a web page wants to display a record date from a database, does it need to ask the view to get the model's data, which brings it from the database? It would be a lot faster if the page just did a quick query to get the information. However, making this call faster introduces a logistical nightmare. Now, you have some layers bypassing others, and your excellent delineation no longer exists. Therefore, keeping this architecture clean requires some code bloat and slowdowns, but reducing them makes the program challenging to maintain.
Best Use Cases: The layered architecture in software engineering is best for prototypes, quick applications, teams with inexperienced developers who need a simple, intuitive architecture, and applications that require very high testability. It's a fantastic, intuitive paradigm. However, as applications scale, other architectures tend to work better.
Event-Driven Architecture
What is event driven architecture? Many programs spend quite a bit of CPU cycles waiting for something to happen. For example, a web server keeps an open socket for whenever a client wants a webpage. A user interface renders itself and then waits for some interaction from the user.
There's a lot of waiting that computer programs do.
The event-driven architecture has a central unit to handle all of these events and then forwards them to the appropriate handlers.
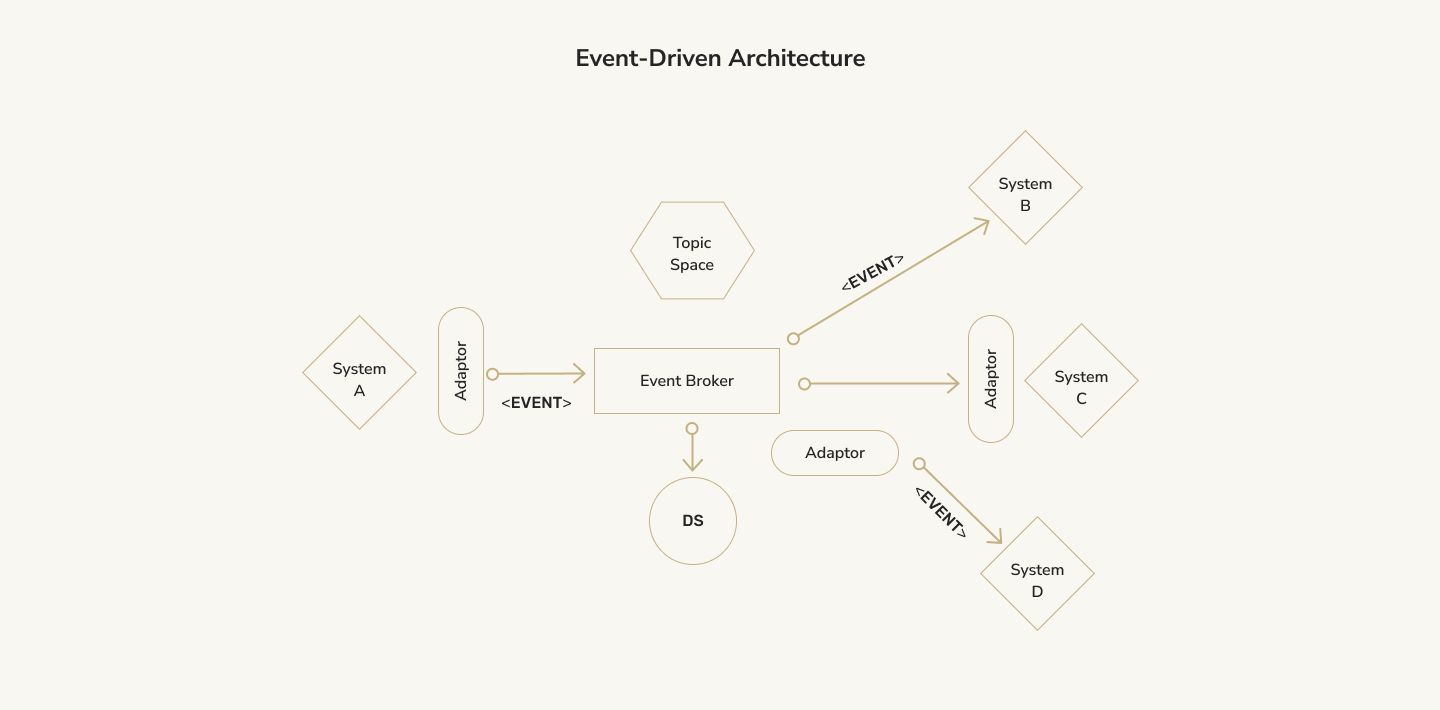
If you've ever heard of Facebook's popular framework, React, and the equally-popular event-driven library, Redux, you've heard of something using this methodology. In Redux, there is a store to receive all events and manage the state of your app. As events come in, they'll dispatch custom-built actions. Those actions then trigger reducers, which take these UI inputs and return the modified application state.
Here's an example of how this works. Let's suppose you have a simple counter application. The count starts at zero, and there's an increment button. The initial state of the "counter" variable is 0. The text on your app displays this state and will auto-update when the state changes (i.e., the text is bound to the state variable). You'd then wire up the control to dispatch an "increment" action. A reducer would set the counter to be counter + 1 if it receives the "increment" action. The reducer then returns this modified state, updating your app's UI automatically.
That's all there is to your app. It's an elegant way of handling events.
Benefits of event-driven architecture: It's clean and very testable. The event-driven architecture lends itself nicely to testing. You can set up the state how you want it to be, mock an event coming in, and verify the application's state has changed the way you expect. For modern web and phone apps, this architecture makes complete sense on the front-end.
Drawbacks: Event-driven architecture has limited use cases. Perhaps another way to put it is that many uses would require significant re-engineering and a different mindset to develop this architecture. Consider a financial application. Sure, in theory, a transaction could be an event that modifies the state (which is a database), and then each account would be a "control" that is "bound" to the new account sum. This idea could work, but it's much more intuitive to think about this type of application as a transaction table and accounts table, with a model, view, and controller to modify them appropriately.
Best Use Cases: Any application or program that must wait for an event to do something useful typically benefits from this architecture. UI and web apps are frequently the top use cases.
Microkernel Architecture
Most applications have a core set of functionality. Think about a text editor, like Notepad, for example. What does it have to do? It has to open files, save files, let the user edit them, and display the text. Notepad has a few other features, but, at its core, this is what the program must do.
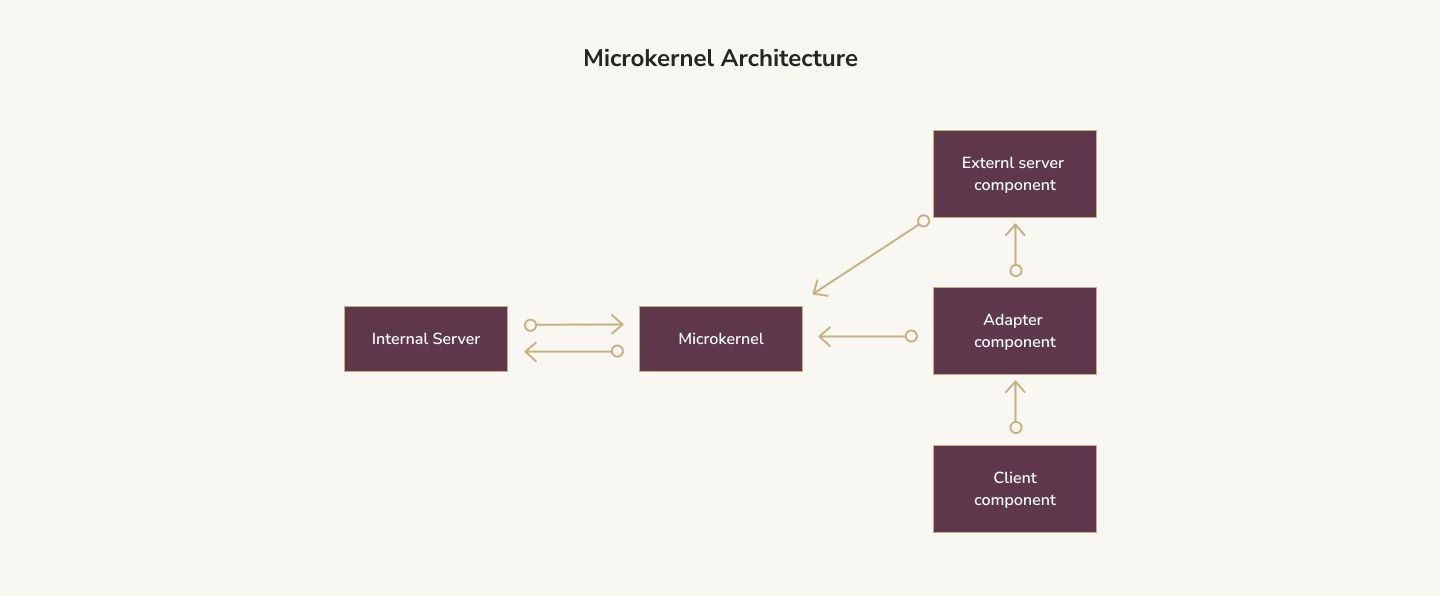
Under the microkernel architecture, the features mentioned above would form Notepad's microkernel. The beauty of this design is that it is extensible. People could then write plugins to add additional features to Notepad to support other use cases. For example, someone might write a plugin to count the number of words or, if a .cpp file is open, compile it via GCC.
Many popular IDEs use this type of architecture. Consider Visual Studio Code. At its core, Code is nothing more than an Electron-based text editor. This core capability is the microkernel. There are plugins to support virtually anything — from Python to JavaScript to even C/C++. These all leverage Visual Studio Code's excellent interface, file editing, and syntax highlighting capabilities.
Benefits: According to best software architecture books, when there's an app that's a good fit for this architecture, it works wonders. It's a fantastic way to think about something like an IDE where you want to build a set of core competencies upon which other plugins can expand. It also helps create a delineated separation of concerns. The app is responsible for a specific set of primary capabilities, and plugins will extend those capabilities.
Drawbacks: It's often challenging to figure out what should and should not go in the microkernel. If you put too little in there, it won't be beneficial. If you put too much, you risk a monolithic architecture that's hard to edit. Figuring out how much to keep in the microkernel is often a development effort in and of itself.
Best Use Cases: Anything requiring a core platform on which to operate is a candidate for this architecture. Operating systems use it. As discussed above, most IDEs use this architecture. Suppose you can separate the app into a base set of rules or paradigms (the microkernel) and some higher-order operations that use those rules (the plugins). In this case and others like it, you should seriously consider the microkernel architecture.
Microservices Architecture
Modern software needs to scale to incredible lengths these days. Amazon receives 200 million unique visitors per month in the United States, and each person browses multiple pages. Amazon uses a tremendous amount of computing power and bandwidth each month.
Amazon isn't running on a mainframe in somebody's basement. There are thousands upon thousands of servers that work tirelessly to give people a fantastic shopping experience that the company provides.
Instead of thinking of the Amazon home page as a single page, think of it as multiple pages. There's an identity section that either shows your name if you're signed in or else encourages you to sign in. There's a section with your recommendations. There are various guides. Of course, you can also search for your favourite products in the search bar. Each of these components comes together in a single cohesive page, but you can split each of these components into small backend services — microservices, to be precise. The next illustration is an example of a microservices architecture diagram.
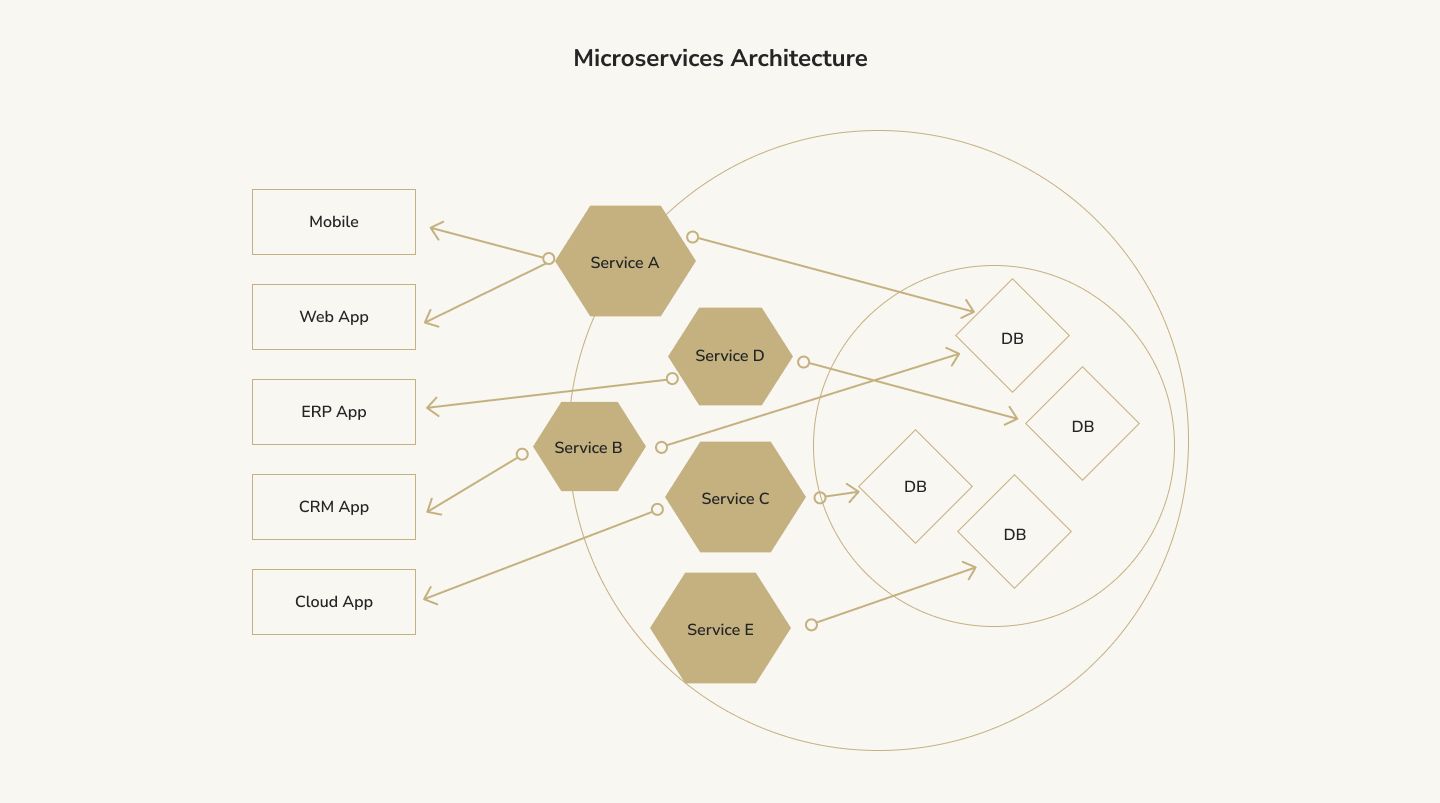
This one of the software security architecture types allows for scalability. You can have hundreds of servers handled if a user is signed in or not. This server farm represents one microservice. You can have a bunch of servers run recommendations. That would be another microservice. You can then have hundreds of servers load-balancing on the front-end to serve the web page as fast as possible.
If you've ever heard of Kubernetes or Docker, you learned about the microservice platforms.
Benefits of microservices architecture: This architecture scales well and is fast. It's also easy to develop for multiple teams (you can have the purchase-oriented team, the rating team, the recommendations team, and so forth). Each unit is responsible for one thing and can scale up or scale down as necessary. There's a good reason that many of the world's leading companies, like Amazon, Microsoft, and Apple, use microservices under the hood.
Disadvantages of microservices architecture: If your project is small, microservices aren't for you. You're not going to run one server for your WordPress blog sending the header, another to send the sidebar, another to send the posts, and so on. Doing so would introduce way too much complexity and overhead. You need an application that requires the level of scale and the number of developers where this architecture shines.
Best Use Cases: Taking into consideration microservices architecture pros and cons, this architecture is most beneficial for large scale websites and apps requiring multiple, independent components to function correctly. With these apps, it's usually possible to separate them into these microservices and gain significant scalability and performance benefits. microservices architecture pros and cons
Space-based Architecture
Most applications have a single source of data, which winds up being a potential bottleneck. A website might store all its users in a database. Even though the front end might have load-balancing to generate the web pages faster, there's still a potential problem with each of these front-end servers needing to access this single database.
Space-based architecture aims to solve this problem. Instead of having a single database, this architecture's idea is to spread out the information spatially.
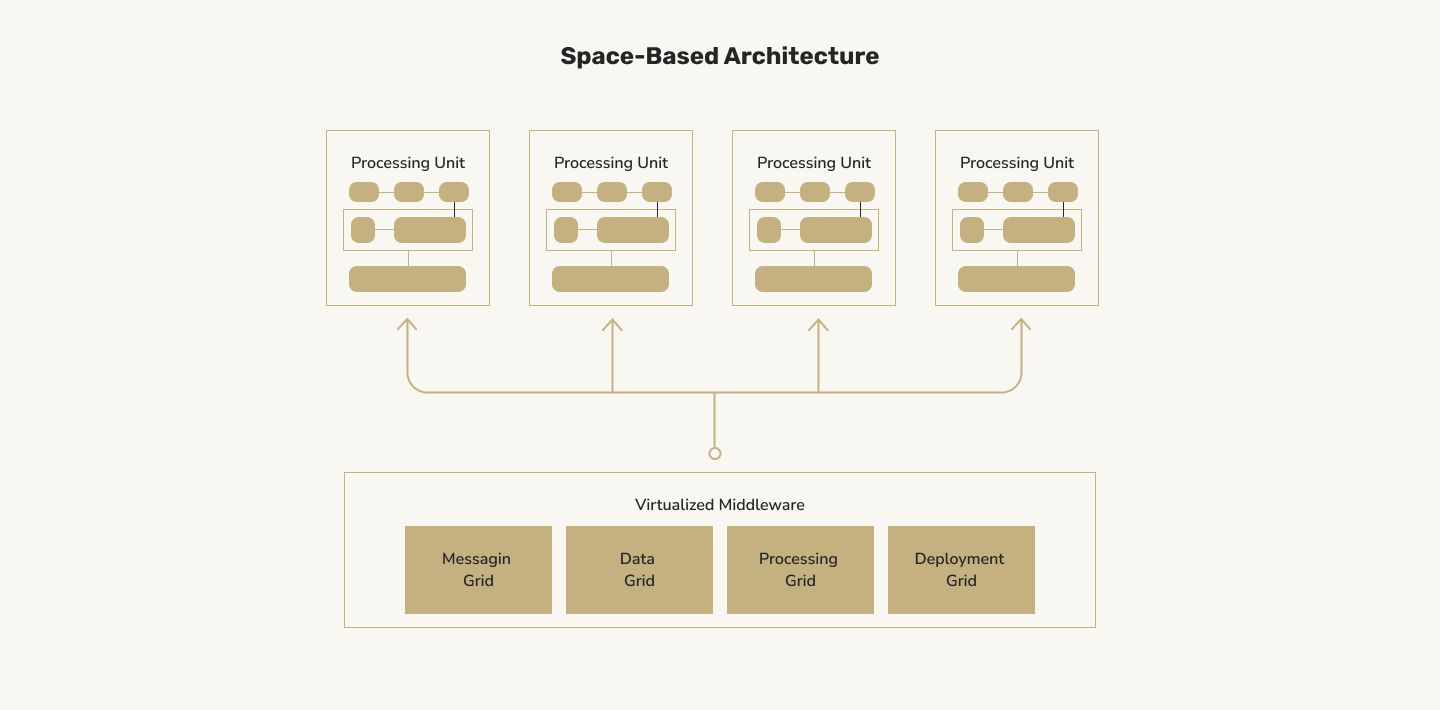
Instead of it residing in one place, what if users A-C lived in memory on one server? Users D-F could reside on the other. When the partitions became too uneven, the system could copy some users from one server to the other as part of a background job. Continually copying and partitioning this data would ensure that the load distributes evenly across the fabric, ensuring that everyone has a stellar experience. Plus, in-memory caches are much faster than those on disk — even if they are on SSDs.
Many complex websites work on this principle. Even though it's not in memory, applications like Apache Hadoop and similar big data programs use this idea. These applications spread and partition the data across multiple machines. When you want to access it, you write a job, which it then splits up into various sub-jobs that each computer executes. Since you now have multiple computers fetching and aggregating smaller chunks of the data, you can accomplish the query much faster than a large monolithic data repository.
Benefits: High-volume use cases are easy. Since everything reads and writes so fast due to the in-memory component, you can handle lots of events all at once.
Drawbacks: Not a significant number of use cases lend themselves to this architecture cleanly. There's quite a bit of developer expertise required to ensure that the data's RAM copies are in-sync and don't become corrupted as new servers come online or old servers fail. It's not a particularly easy paradigm to use.
Best Use Cases: This software defined architecture is best for high-volume low-importance data. Telemetry is often a great use case for this architecture. Let's say you want a system that stores clickstream and impression data on what users are doing with your app. You could fire up multiple servers, each with an in-memory database. When an event comes in, a load balancer could fire it to one of these servers, which could immediately put it into memory. A background job could take these events and consolidate them into a chronological stream for data mining purposes. Since clicks are not bank transactions, even if this data isn't 100% perfect, it'll still be good enough to gain valuable insights.
Impressit's Experience with Software Architecture
Impressit has significant experience in the domain of software architecture consulting. We have worked on countless software projects and always clearly understand requirements and define the proper software architecture. We've seen everything from projects where the architecture was never clearly explained to projects where the architecture is concrete.
Throughout our experience, we've noticed that it's far easier to join an existing project with a well-thought-out architecture than to join one that has none. Much like an engineer requests a building's blueprints before making significant changes, it's easier for software engineers to make changes if they understand the architectural design choices. Reading the code and understanding what it does becomes much more intuitive.
When we start a new project, we always take a couple of weeks to understand the requirements carefully. During this time, our expert software architects create the perfect architecture for your particular need. Most of the time, an app doesn't use just one architecture. Instead, it uses many. The backend might have microservices, and the app might use the event-driven model. We take the time to define each component carefully, how they relate to one another, and which best practices we'll use to create the best solution.
This step is vital for a few reasons:
- It acts as a blueprint for our devs to ensure they're producing the best possible software for you.
- If you later decide to supplement your team with other devs, whether in-house or choosing outsourced software product development professionals, they'll be able to make changes much more quickly as they'll see the design decisions we made.
- The end product will be of high quality, well-tested, and ready for your users to enjoy when it has the best software architecture.
Impressit's experience helps ensure that you'll always get the best architecture for your business needs.
Choosing the Right Software Architecture Will Make or Break the Project
Choosing the right software architecture is the difference between a successful project and one that runs into perpetual problems. Getting the wrong architecture can often mean dealing with bloated, buggy code that is tricky for developers and equally frustrating for consumers.
On the other hand, with clearly defined requirements and a well-thought-out architecture, you'll have the confidence that your application will be able to handle everything, no matter how successful and widely used it may be.
If you would like us to help ensure that your project's architecture will have the best scalability, reliability, and usability, please contact us. We have extensive expertise in this domain and would love to discuss your project architecture with you.
Andriy Lekh
Other articles